系统架构演化历程-初始阶段架构
<img data-rawheight="367" data-rawwidth="516" src="https://pic4.zhimg.com/13bd5a6612620fdf51c8987ab3eb1273_b.jpg" class="origin_image zh-lightbox-thumb" width="516" data-original="https://pic4.zhimg.com/13bd5a6612620fdf51c8987ab3eb1273_r.jpg">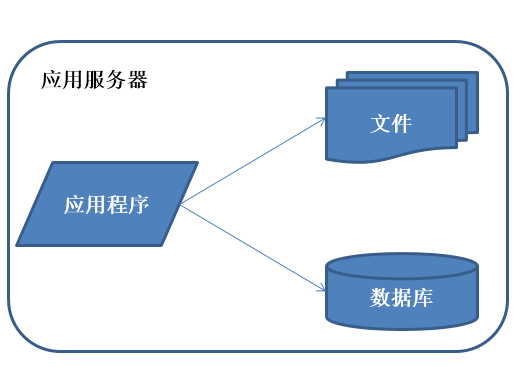
系统架构演化历程-应用服务和数据服务分离
<img data-rawheight="408" data-rawwidth="510" src="https://pic2.zhimg.com/c2ff4e51eec15231b2f69fe6a4038239_b.jpg" class="origin_image zh-lightbox-thumb" width="510" data-original="https://pic2.zhimg.com/c2ff4e51eec15231b2f69fe6a4038239_r.jpg">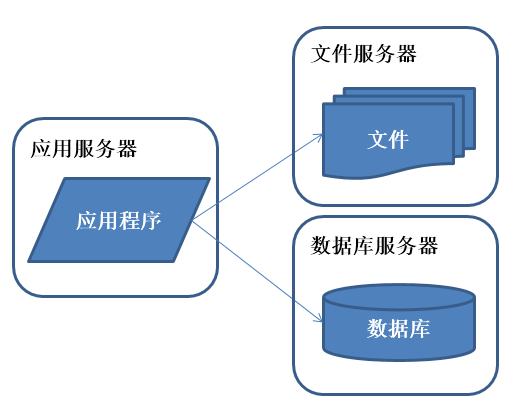
系统架构演化历程-使用缓存改善性能
<img data-rawheight="525" data-rawwidth="526" src="https://pic4.zhimg.com/7f5890aefa3a065ea91baa33e928d59b_b.jpg" class="origin_image zh-lightbox-thumb" width="526" data-original="https://pic4.zhimg.com/7f5890aefa3a065ea91baa33e928d59b_r.jpg">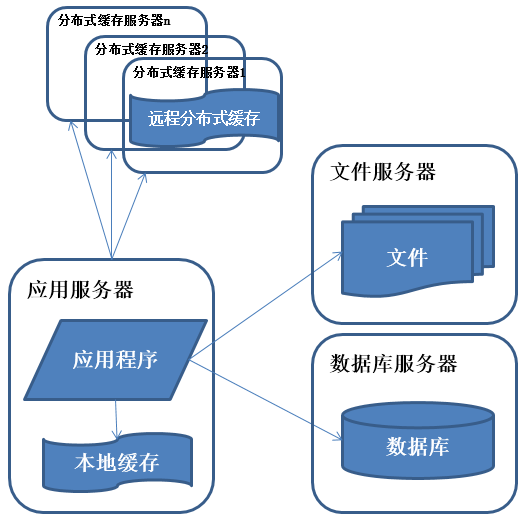
系统架构演化历程-使用应用服务器集群
<img data-rawheight="548" data-rawwidth="576" src="https://pic4.zhimg.com/66b50d0767750b0ff30d00d13a2a1963_b.jpg" class="origin_image zh-lightbox-thumb" width="576" data-original="https://pic4.zhimg.com/66b50d0767750b0ff30d00d13a2a1963_r.jpg">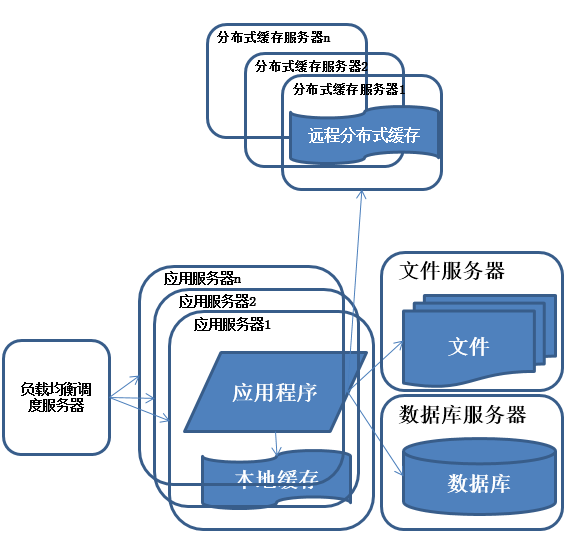
系统架构演化历程-数据库读写分离
<img data-rawheight="549" data-rawwidth="568" src="https://pic2.zhimg.com/e8cb08ede220e1f41459374e3ef72f85_b.jpg" class="origin_image zh-lightbox-thumb" width="568" data-original="https://pic2.zhimg.com/e8cb08ede220e1f41459374e3ef72f85_r.jpg">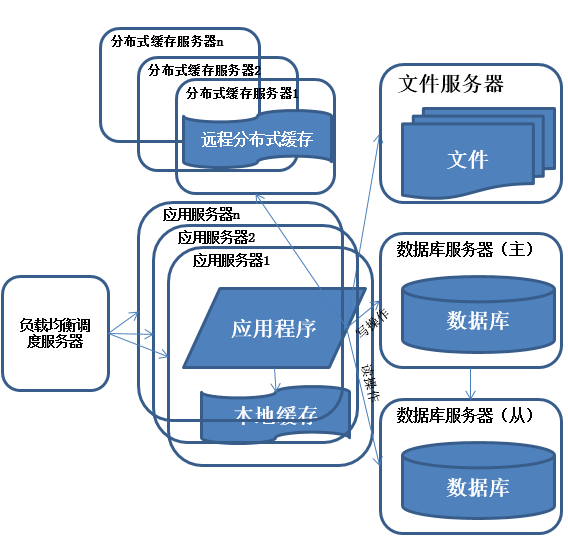
系统架构演化历程-反向代理和CDN加速
<img data-rawheight="520" data-rawwidth="711" src="https://pic2.zhimg.com/a2db8db8b2d7500adf6135c76d6323f9_b.jpg" class="origin_image zh-lightbox-thumb" width="711" data-original="https://pic2.zhimg.com/a2db8db8b2d7500adf6135c76d6323f9_r.jpg">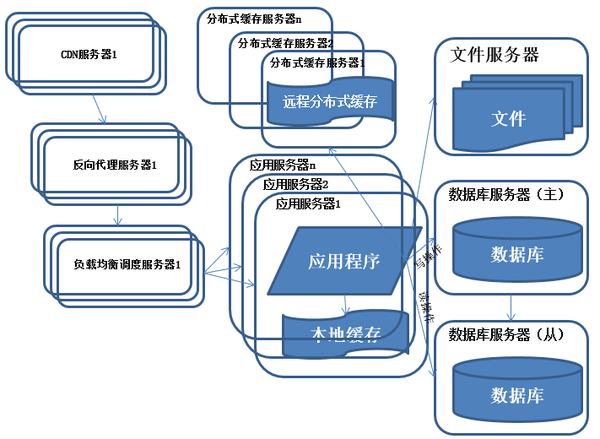
系统架构演化历程-分布式文件系统和分布式数据库
<img data-rawheight="526" data-rawwidth="920" src="https://pic1.zhimg.com/ea091b2c553a7771695a4c707b091668_b.jpg" class="origin_image zh-lightbox-thumb" width="920" data-original="https://pic1.zhimg.com/ea091b2c553a7771695a4c707b091668_r.jpg">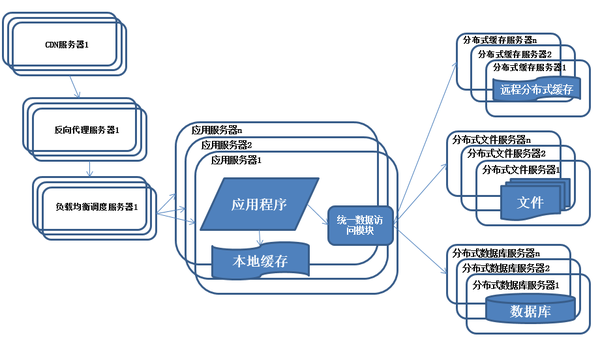
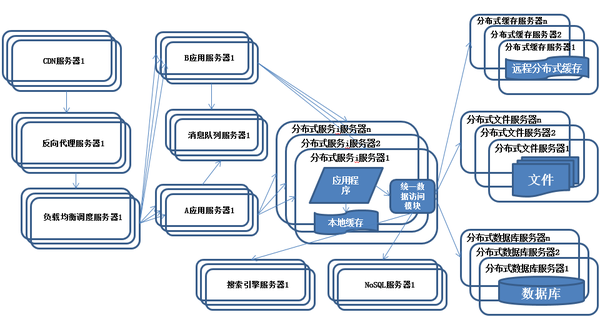
系统架构演化历程-使用NoSQL和搜索引擎
<img data-rawheight="518" data-rawwidth="936" src="https://pic1.zhimg.com/7e25f96d31da26661c078b847c8acc44_b.jpg" class="origin_image zh-lightbox-thumb" width="936" data-original="https://pic1.zhimg.com/7e25f96d31da26661c078b847c8acc44_r.jpg">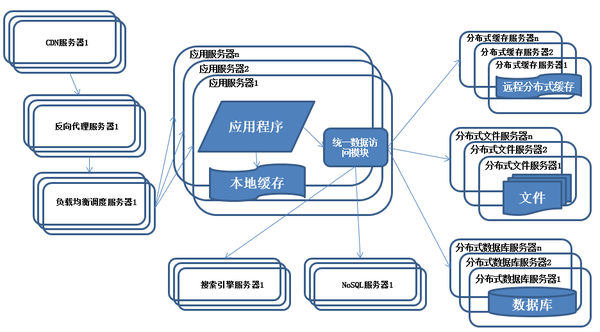
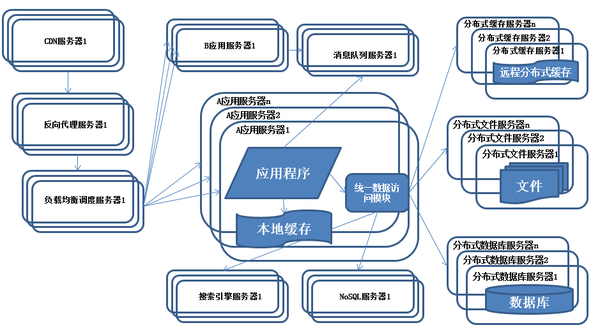
系统架构演化历程-业务拆分
<img data-rawheight="520" data-rawwidth="939" src="https://pic2.zhimg.com/51faaff90df43279c82ffd6a6b587135_b.jpg" class="origin_image zh-lightbox-thumb" width="939" data-original="https://pic2.zhimg.com/51faaff90df43279c82ffd6a6b587135_r.jpg">